AI
Athena: How Well Can Transformers Play Chess?
Joshua Gao
28 Oct 2025

Presenting Athena: a 270M parameter transformer-based chess engine that reaches an ELO of 1959 by distilling Stockfish 17 across 15.3 billion labeled positions.
Overview
Teaching a neural network to play strong chess has traditionally required either massive self-play compute (as in AlphaZero) or hand-crafted evaluation functions. A more efficient alternative is knowledge distillation: train a model to mimic the output of a state-of-the-art engine rather than discover chess from scratch. Athena takes this approach, distilling Stockfish 17 into a compact transformer that can evaluate any board position and move pair in a single forward pass, with no search required. This work is heavily inspired by Ruoss et al., who demonstrated that transformers can achieve grandmaster-level play through a similar distillation strategy. Athena extends their work by introducing mating bins and exploring alternative output encodings to address a key weakness in the original approach.
Method
Chessbenchmate Dataset
The dataset consists of all unique board positions drawn from 10 million Lichess games. For each unique position, every legal move was evaluated by Stockfish 17 for 0.05 seconds at unbounded depth, producing both a win probability and a mate-in-N label where applicable.
Stockfish's centipawn score is converted to a win probability using a sigmoid function:
This results in 15.3 billion position-move pairs in total. Positions with a forced mate are labeled with a win probability of 0% or 100% depending on which side is being mated.
Architecture
Athena is a 270 million parameter transformer trained on the Chessbenchmate dataset. ResNet, Vision Transformer (ViT), and Mamba architectures were also explored during initial experiments, but the standard transformer consistently outperformed them and was selected for the full training run.
Input Encoding
Each position is converted from a FEN string into tokens by assigning each possible FEN character a unique integer ID, totaling 78 character tokens. The UCI move is similarly encoded across all legal moves for all pieces, giving 1968 possible move tokens.
fen_tokens → [0, 34, 12, 7, ..., 45]
move_token → 843
Output Encoding
The win probability and mate-in-N labels from Chessbenchmate are discretized into evaluation bins, where is the number of win probability bins and is the maximum mate distance tracked. Lower bin indices correspond to worse outcomes; higher indices correspond to stronger positions. The full bin structure is:
[ negative mates | win prob bins | positive mates | checkmate ]
# or
[-M, ..., -2, -1, wp_0, wp_1, ..., wp_(k-1), +M, ..., +2, +1, #]
Experiments
Athena Training
Model quality is evaluated on a held-out set of 10,000 chess puzzles. Puzzle accuracy is a strong proxy for playing strength: a model that can find the only correct move in a tactical position tends to play better chess overall.
Athena achieves a puzzle accuracy of 80.15% after training on 40% of Chessbenchmate, covering over 6.12 billion position-move pairs. Training was stopped before a full epoch due to diminishing accuracy gains relative to additional compute cost; the learning curve had largely flattened by this point.
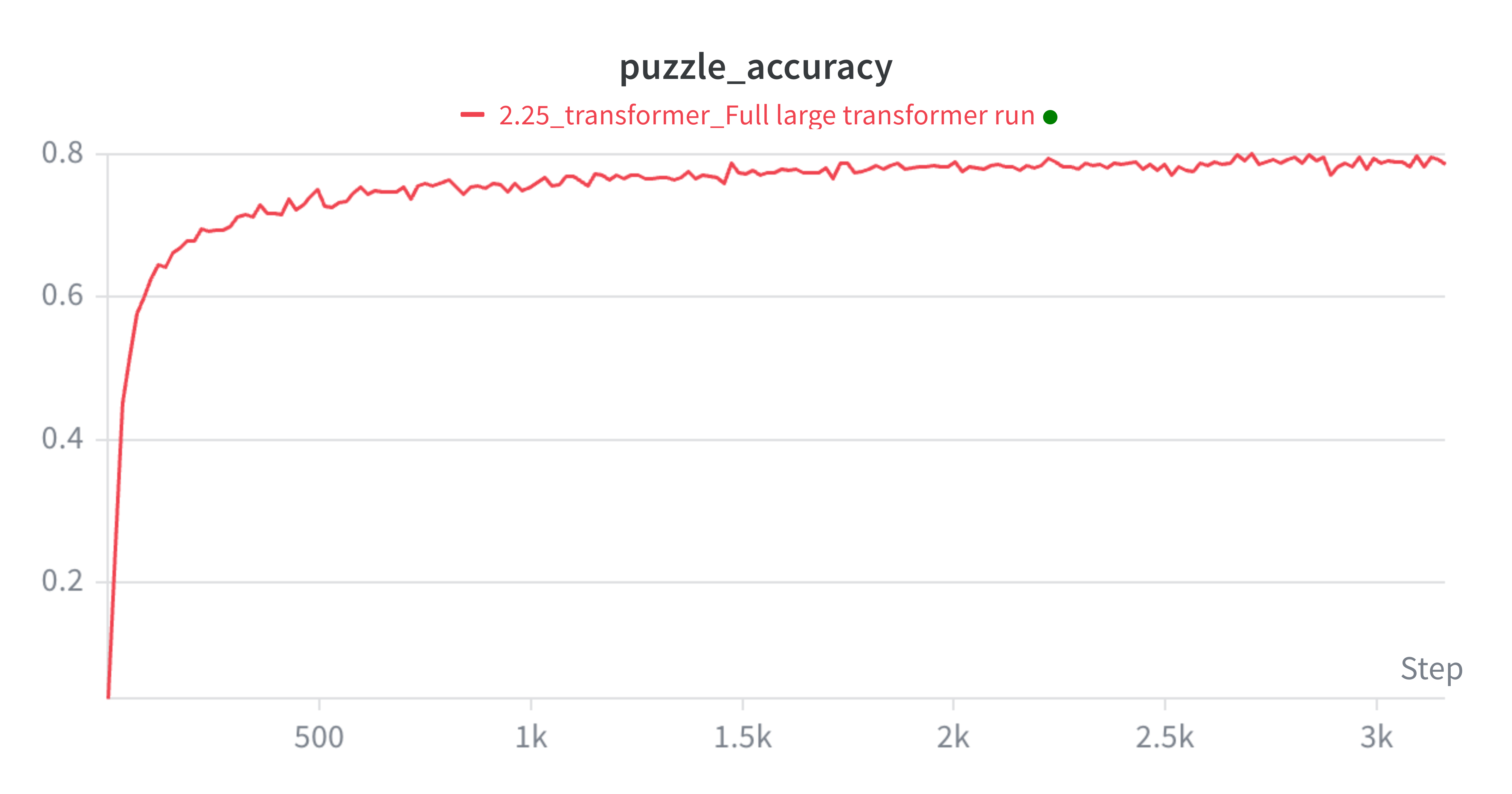
As expected, puzzle accuracy degrades as puzzle difficulty increases. Even so, Athena solves a meaningful fraction of the hardest puzzles in the set.
In live play, Athena reaches a peak ELO of 1959 on Lichess competing against other bots, a strong result for a model with no search at inference time. You can challenge Athena or watch it play here.
Other Bin Values and Encoders
A well-known failure mode in action-value distillation is what Ruoss et al. call "Indecisiveness in the face of overwhelming victory." When the model is in a clearly winning position, many candidate moves map to the same high output bin. Without position history, the model has no incentive to make progress and tends to shuffle pieces back and forth. Ruoss et al. resolve this by handing off to Stockfish whenever an "inevitable win" is detected, a pragmatic but inelegant workaround.
Athena attempts to solve this more cleanly by introducing dedicated mating bins, which give the model a finer-grained incentive to shorten forced mates. Two additional variants were also tested: dramatically increasing the total number of bins, and applying an arcsin output encoder to spread probability mass more evenly across the bin range.
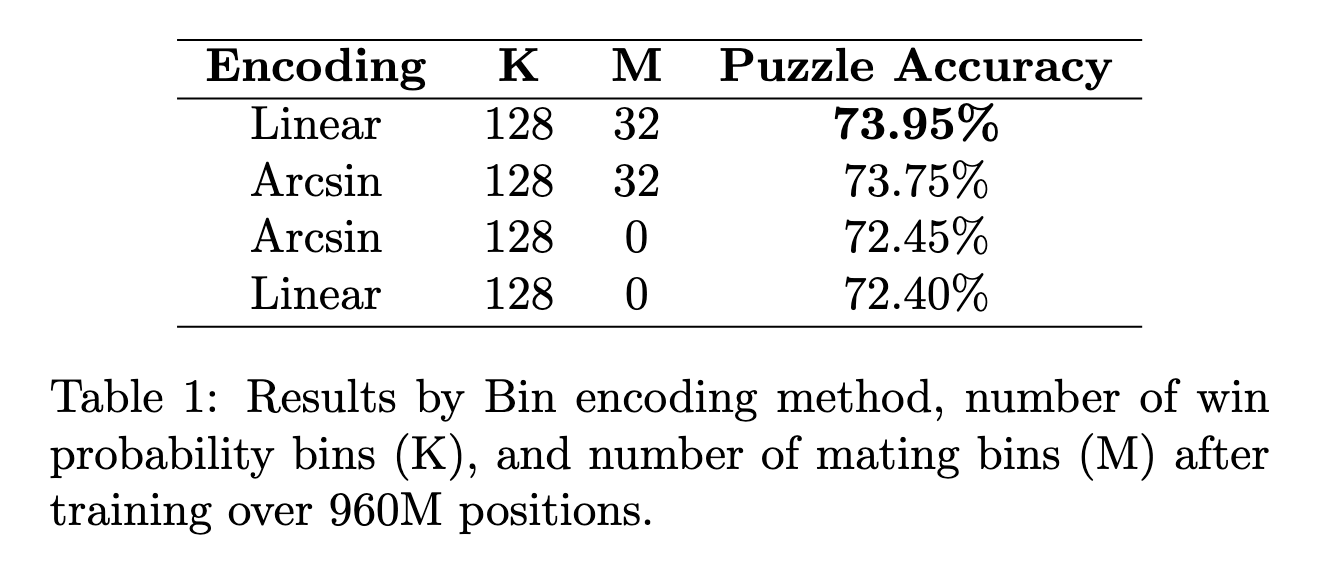
Adding mating bins improves puzzle accuracy, though the margin is modest. Increasing the bin count and switching to arcsin encoding neither help nor hurt significantly, suggesting the baseline win probability bins already capture most of the useful signal.
Limitations
Mating bins partially mitigate the indecisiveness problem, but many winning positions have no clear forced mate; they require a long technical conversion that a myopic evaluation function will repeatedly defer. Providing the model with some level of move history is a promising direction to address this, as it would give the model the context to recognize that it is making progress. Additionally, the current setup trains the model to evaluate position-move pairs rather than to directly predict the best move; a policy head or a best-move objective might lead to more decisive play in unambiguously winning positions.
Conclusion
Athena demonstrates that a 270M parameter transformer, trained purely through Stockfish distillation on 6+ billion positions, can reach a competitive 1959 ELO without any search at inference time. The introduction of mating bins provides a modest but consistent improvement over the baseline encoding, and the ablation results give a clearer picture of where the remaining headroom lies. Compared to Ruoss et al., Athena trades peak performance for accessibility: the full pipeline, from dataset generation to a deployable bot, is achievable without datacenter-scale compute. There is meaningful room to improve with a full training epoch, move history, and a best-move training objective, all of which are left for future work.